Hold on… Do you also think that number 10 means something special? I don’t know. It feels rather different. I can’t believe we’re doing this! We’re getting there!
Copy Data Using IDCAMS System Utility
IBM Master the Mainframe Part Two – Challenge #10
This seems like a very short challenge. I will learn how to copy data using IDCAMS into various data set types. This requires me to edit CH10JCL.
Please observe line 000013 on the image above. There are two sets of @’s that I need to replace. The REPROdocumentation indicates that the primary command is REPRO. So the @@@@@ at col 3-7 will be changed to REPRO.
The 13th line actually copies the data set, it needs an INFILE and OUTFILE. We need to copy just about 6 data sets so let’s duplicate line 13 5 times by using the r5 line command.
Then when that’s done… just change each @@@@ to the DDNAME from line 6 to 11. Let’s take a look at what I have now.
The yellow characters indicate my changes. The first two are only three characters, so just press spacebar to overwrite the unnecessary character.
What’s left to do now is to just execute the JCL using submit ; =sd ; st and view the job output. JOB03845 SUBMITTED!
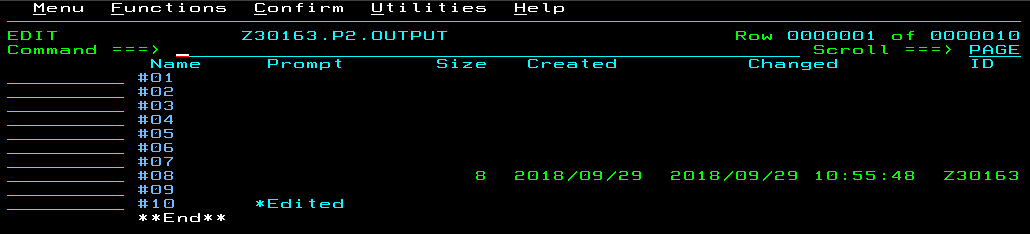
I copied the output to P2.OUTPUT(#10) using xdc just like before. Let’s check the output, it should show REC-TOTAL 8 in the STATISTICS section of the VSAM data set attribute output.
There it is! It took me a while to find it though!
What about you?
Are you also completing some challenges? Which ones?
Why am I doing the challenges so slow? I heard they update the leaderboards every Friday. I want to have finished part 2 all of its challenges by next Friday the 12th of October. So expect a load of blog posts by then! Don’t worry about all the notification mails though, I’ll merge some challenges into one blogpost.
Data, Data Sets, and Unix files
IBM Master the Mainframe Part Two – Challenge #09
In this episode of Kevin’s Coding Blog you’ll learn a thing or two about VSAM and NON-VSAM data sets.
NON-VSAM includes
1) Sequential
2) PDS, Partitioned Data Set
3) PDS/E, Partitioned Data Set/Extended
VSAM includes
1) KSDS, Key Sequences Data Set
2) ESDS, Entry Sequenced Data Set
3) RRDS, Relative Record Data Set
4) LDS, Linear Data Set
We use parameters inside the JCL to let the system know which data set to make. This is also the assignment for today. I need to replace all @-characters with the appropriate parameters to create the correct data sets.
&SYSUID..CH9.SEQ created as a sequential data set type
&SYSUID..CH9.PDS created as a partitioned data set type
&SYSUID..CH9.PDSE created as a partitioned data set extended type
&SYSUID..CH9.KSDS created as a VSAM Key Sequenced Data Set type
&SYSUID..CH9.ESDS created as a VSAM Entry Sequenced Data Set type
&SYSUID..CH9.RRDS created as a VSAM Relative Record Data Set type
&SYSUID..CH9.LDS created as a VSAM Linear Data Set type
In particular all of the data sets above. &SYSUID. is automatically replaced by my ID, Z30163.
Now what do I need and where can I learn which parameters I need to pass? IBM provided the links beneath.
//* --------------------------
// IF RC =0THEN
//* -------------------------- //RESULT EXECPGM=IKJEFT01 //SYSTSPRT DD SYSOUT=*
//SYSTSIN DD *
LISTDS CH9.SEQ
LISTDS CH9.PDS
LISTDS CH9.PDSE
LISTC ENT(CH9.KSDS) ALL
LISTC ENT(CH9.ESDS) ALL
LISTC ENT(CH9.RRDS) ALL
LISTC ENT(CH9.LDS) ALL
//* --------------------------
// ENDIF
There are three EXEC statements. At first it deletes any existing CH9 related data set. Then the second statement creates NONVSAM data sets. The last statement creates VSAM data sets. There’s also a last EXEC statement that executes only when RC equals to 0.
The first three should be simple, I just need to assign the correct DSORG. The first needs to be a sequential data set type which is PS. PS stands for physical sequential. The other two require a DSORG and PDSE also requires a DSNTYPE.
So I need to create a PDS and PDSE data set. Creating the PDSE requires the DSORG=PO and DSNTYPE=LIBRARY. The SMS will choose whether it will be a PDS or PDSE. I guess it’ll pick PDSE because I added the DSNTYPE. To create a PDS data set we leave out the DSNTYPE.
Observe the changes I made in the code above. That was fairly easy, VSAM on the other hand… oof. Let’s first create the key-sequenced data set (KSDS). The tutorialspoint KSDS tutorial states that we must code INDEXED inside the DEFINE CLUSTER and it seems that hasn’t been done yet. Add that and check! Same but different for the ESDS data set, we must code NONINDEXED inside the DEFINE CLUSTER.
What’s the deal with INDEXED and NONINDEXED? Well, ESDS is non-index and KSDS is. This means that there are no index component keys present inside an ESDS data set. Which means that an ESDS data set may contain duplicate keys. More info at tutorialspoint.com.
Regarding RRDS, we must also code NUMBERED inside the DEFINE CLUSTER command. Easy! Then LDS needs LINEAR. I wasn’t all too sure about the LINEAR statement but after some research here, I found out that LINEAR is used to specify that this CLUSTER needs to be of type LINEAR. Let’s take a look at the result!
Don’t forget, use the ? sign to ask information about the job. I’ve printed the output to P2.OUTPUT. Let’s check if I created the data sets…
Yes I did! This challenge probably would’ve taken me about 5-10 minutes if I wasn’t writing this blog whilst doing the challenge.
The screenshot above is the copied output inside P2.OUTPUT(#09). No errors or anything! I’m a happy man!
6 + 15 = 21
Jup, that’s right! That’s the amount of challenges left. I’ve completed about 10 if you include the first part. I know, 10 isn’t all too much. But each challenge also has a very fun blogpost so… Anyway, counting how much you have left to do is always a bad practice. Either you get motivated or you get demotivated. It’s ok in this case though! I’m fine!
What about you? What’s been keeping you motivated?
I know most of the people that read this blog probably have a programming background. This challenge is about bits, bytes, hexadecimal, ASCII and EBCDIC. I assume you know most of them, but what is EBCDIC?
z/OS its default encoding is EBCDIC. EBCDIC stands for Extended Binary Coded Decimal Character Interchange Code. It’s an 8-bit-standard way to store letters and punctuation marks.
In each table cell above, the first row is an abbreviation for a control code or (for printable characters) the character itself; and the second row is the Unicode code (blank for controls that don’t exist in Unicode).
I need to edit Z30163.PDS.DATA member named MIX. That means, issue primary command =3.4 and tab to Dsname level and hit enter. Then edit Z30163.PDS.DATA and select MIX.
Only some lines are readable. Let’s reset and display the cols on line 000001. Yes, on a line. Not the primary command cols. Next, issue the hex on primary command to view the hexadecimal representation of each character.
It looks weird doesn’t it? Let me visualise it a bit better for you.
EBCDIC uppercase T is hexadecimal xE3 where x means hexadecimal. Same way around if you issue the source ascii primary command.
The word binary is mispelled on line 000004 and 000005. It is written as binery instead of binary. I can just overwrite the e with an a, but where’s the fun in that? To change the e to an a I’ll change 8,5 to 6,1.
The CHANGEcommand can also do the job by using CHANGE ALL binery binary.
As you can see in the image above. The change command changed binery to binary. Now I’m left with a packed decimal. They can only be viewed when using the hex on mode. Line 000007 can be represented as the 2×3 matrix [[1,0,8],[2,1,C]]. Let’s take a look at the Packed Decimal table.
So the 2×5 matrix [[1,3,5,7,9],[2,4,6,8,C]] equals to 123,456,789 (+). What would our matrix equal then? Does it equal to 12018 (+)? I’m a bit sceptical as it’s not exactly 2018. Is the ‘1’ wrong? I need to enter the decoded “packed decimal” value in EBCDIC format in the line 000008 text area colums 1-5 and the sign character in column 6.
That leaves me with this.
It’s funny to think that a human can learn a character format in less than 5 minutes. I’m impressed with myself. Let’s copy all 8 lines using the line command c8 and add it to our P2.OUTPUT(#08) data set.
Copied! I’ve just verified the creation and contents of member #08 and all seems ok!
Next up
This was refreshing! Challenge #07 didn’t get me demotivated or anything but it helps to have a short challenge once in a while! Don’t get me wrong, I’m not lazy 😉
Next challenge is BIG! (big as in fun and meaning, not length) I’m excited! I’m going to learn how to allocate 7 unique types of z/OS data sets. I also get to watch about 4 video’s about VSAM, DSORG and DSNTYPE.
I bet you don’t know what the features image is used for don’t you? It’s a punched card with the EBCDIC character set on it. Vintage!
How many video’s did you watch this week?
I use cookies to ensure that I give you the best experience on my website. If you continue to use this site I will assume that you are ok with it.Ok